論文概要
タイトル: GLEE: General Object Foundation Model for Images and Videos at Scale
リンク: arXiv:2312.09158
今回は、画像処理分野で注目されている新しい基盤モデル 「GLEE」 について紹介します。
GLEEは、画像や動画内の「物体」を包括的に理解するために設計されたモデルで、検出、セグメンテーション、追跡(トラッキング)、識別といった多様なタスクを一つのモデルでこなすことができます。
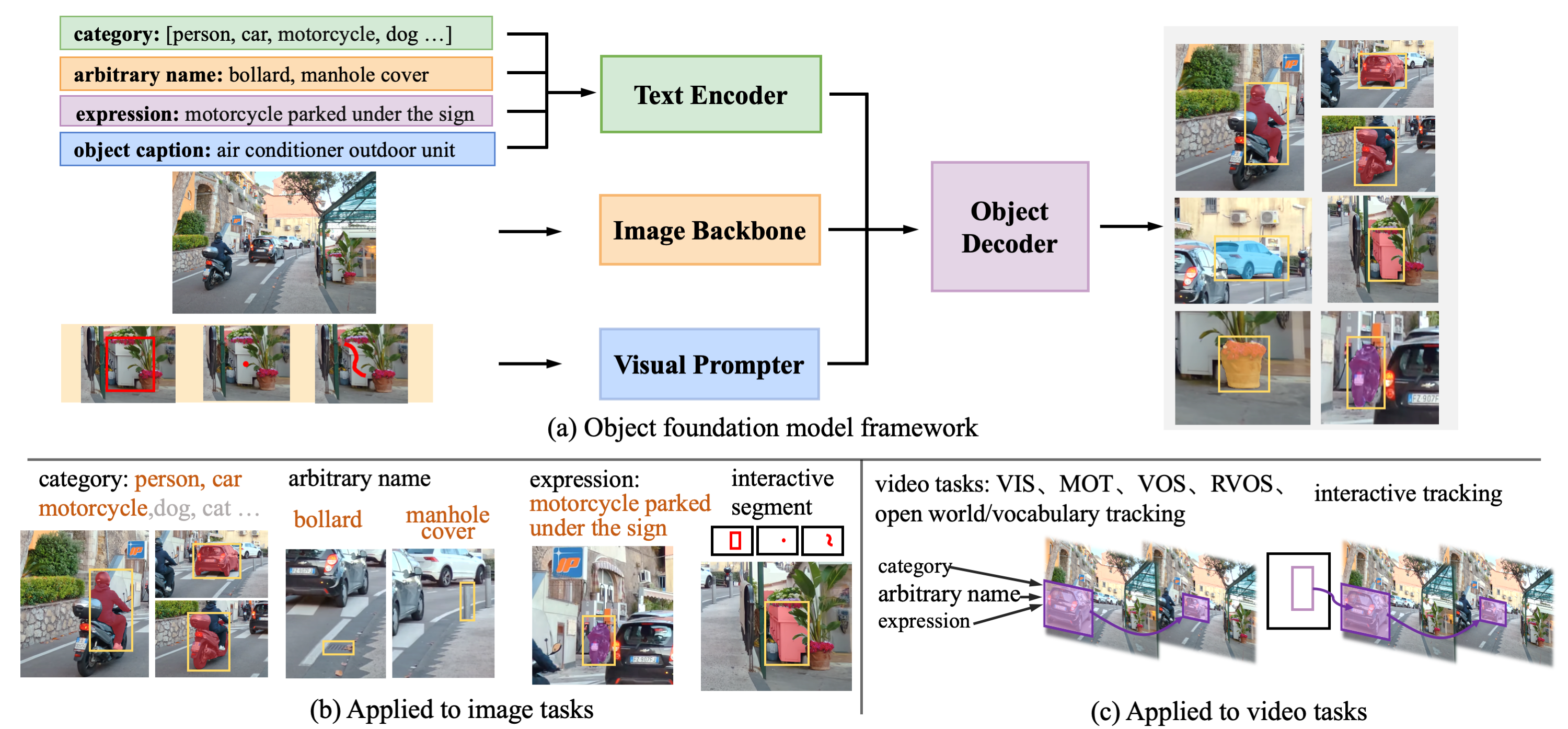
出典: FoundationVision/GLEE GitHub
コア・メソドロジー(手法)
GLEEの最大の特徴は、「統一されたフレームワーク」 にあります。
- マルチモーダル入力: 画像エンコーダ、テキストエンコーダ、そして視覚プロンプターを統合し、画像だけでなく言葉や視覚的な指示(プロンプト)によって対象を特定できます。
- 大規模学習: 500万枚以上の画像を含む多様なデータセットを使用し、「多粒度共同教師あり学習(Multi-granularity joint supervision)」を行っています。これにより、教師データのレベルが異なる様々なソースから効率的に学習し、汎用的な物体の表現を獲得しています。
- スケーラビリティ: 自動ラベリングされた大量のデータを取り込むことで、ゼロショット(学習データにない未知の物体への対応)能力を大幅に向上させています。
実験結果と成果
GLEEは、特定のタスク専用に調整(ファインチューニング)することなく、多くのベンチマークでSOTA(State-of-the-Art:最高記録)を達成しました。
- 動画トラッキング: TAO, BURST, LV-VISといった動画データセットにおいて、従来のモデルを大きく上回るゼロショット転移性能を示しました。
- 画像タスク: COCOやLVISといった主要な画像ベンチマークでも、既存の汎用モデルを凌駕し、専用モデルに匹敵する精度を出しています。
- データのスケール: 学習データを増やせば増やすほど、下流タスク(具体的な応用タスク)での性能が向上することが確認されています。
言語モデリング分野への意義
私たちソフトチームとして特に注目すべきは、GLEEが 大規模言語モデル(LLM)の「目」になり得る という点です。
現在の多くのLLMは、テキスト情報の処理には長けていますが、視覚的な「物体レベルの情報」を詳細に把握するのは苦手です。
GLEEを基盤モデルとしてLLMに統合することで、画像内の具体的な物体を認識し、それについて対話できるような、より高度な マルチモーダルLLM(mLLM) の構築が可能になります。
これは、汎用人工知能(AGI)の実現に向けた、視覚理解の側面からの大きな一歩と言えるでしょう。
まとめ
GLEEは、単なる画像認識モデルを超え、言語モデルと視覚世界をつなぐ重要な架け橋となる可能性を秘めています。
今後のマルチモーダルAI開発において、このモデルのアーキテクチャや学習手法は非常に参考になるはずです。